I read up on how to make good MCQs and one very important point is to use as many functional distractors as possible. This is harder than it sounds.
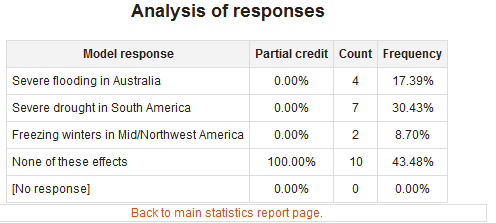
Something that would be easy would be to identify likely non-functional distractors. They are simply answers that few students chose. The papers I read suggest that eliminating them from MCQs is an effective way to improve question quality.
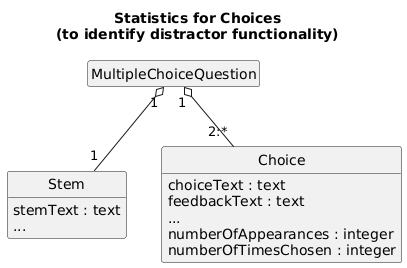
I'm suggesting adding statistics to questions that would keep track of this data. Something simple would work. Each multiple-choice question in the bank has added metadata keeping track of the number of times a choice appears (numberOfAppearances) and the number of times it gets chosen (numberOfTimesChosen). Here's a domain model of the problem (not a database model):
With this data, it would be very easy to identify questions that have non-functional distractors. I find this statistic much more useful to improve my questions than the current set of statistics that are at a "question" level only.
Of course, editing the text of a Choice should effectively re-set the stats to 0. There might be other subtleties on how to handle the data based on use cases. Actually, modeling distractors as a separate entity (independent of questions) is interesting, since I often re-use the text. A good distractor (functional) is useful in several questions. I can see the question editor having a feature to "suggest" functional distractors from other questions in the same category, for example. But these are all features that require more work. The basic feature of calculating the efficacy of a distractor is a simple start.